Docker 入門
Author:Anda Toshiki
Updated:2 months ago
Words:2.2k
Reading:8 min
ここまでの章で扱ってきたハンズオンでは,単一のサーバーを立ち上げ,それに SSH でログインをして,コマンドを叩くことで計算を行ってきた. いわば,パーソナルコンピュータの延長のような形でクラウドを使ってきたわけである. このような,インターネットのどこからでもアクセスできるパーソナルコンピュータとしてのクラウドという使い方も,もちろん便利であるし,いろいろな応用の可能性がある. しかし,これだけではクラウドの本当の価値は十分に発揮されていないと言うべきだろう. (#chap_cloud_basics) で述べたように,現代的なクラウドの一番の強みは自由に計算機の規模を拡大できることにある. すなわち,多数のサーバーを同時に起動し,複数のジョブを分散並列的に実行させることで大量のデータを処理してこそ,クラウドの本領が発揮されるのである.
本章からはじまる 3 章分 (Docker 入門, (#sec_fargate_qabot), (#sec_aws_batch)) を使って,クラウドを利用することでどのように大規模な計算システムを構築しビッグデータの解析に立ち向かうのか,その片鱗をお見せしたい. とくに,前章で扱った深層学習をどのようにビッグデータに適用していくかという点に焦点を絞って議論していきたい. そのための前準備として,本章では Docker とよばれる計算機環境の仮想化ソフトウェアを紹介する (figure_title). 現代のクラウドは Docker なしには成り立たないといっても過言ではないだろう. クラウドに限らず,ローカルで行う計算処理にも Docker は大変便利である. AWS からは少し話が離れるが,しっかりと理解して前に進んでもらいたい.
機械学習の大規模化
先ほどから"計算システムの大規模化"と繰り返し唱えているが,それは具体的にはどのようなものを指しているのか? ここでは大規模データを処理するための計算機システムを,機械学習を例にとって見てみよう.
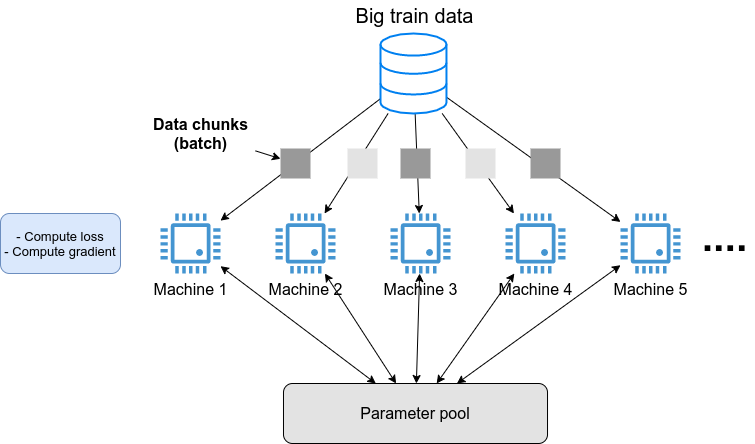
(#sec_scientific_computing) で紹介した GPT-3 のような,超巨大な数のパラメータを有する深層学習モデルを学習させたいとしよう. そのような計算を行いたい場合,一つのサーバーでは計算力が到底足りない. したがって,典型的には figure_title に示すような計算システムの設計がなされる. すなわち,大量の教師データを小さなチャンクとして複数のマシンに分散し,並列的にニューラルネットのパラメータを最適化していくという構造である.
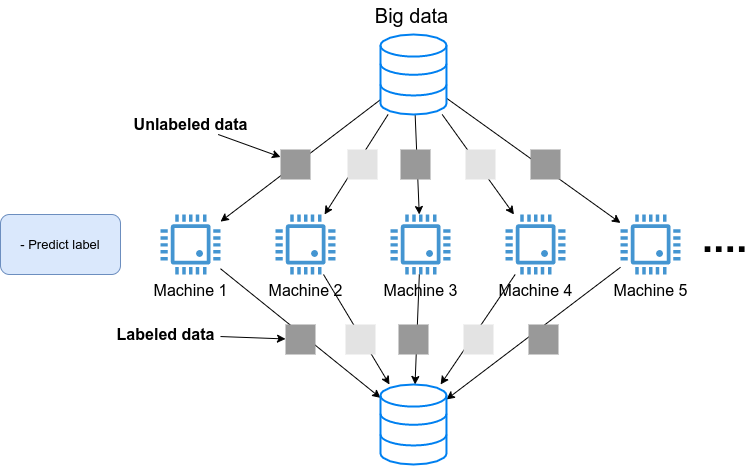
あるいは,学習済みのモデルを大量のデータに適用し,解析を行いたいとしよう. たとえば, SNS のプラットフォームで大量の画像が与えられて,それぞれの写真に何が写っているのかをラベルづけする,などのアプリケーションを想定できる. そのような場合は, figure_title のようなアーキテクチャが考えられるだろう. すなわち,大量のデータを複数のマシンで分割し,それぞれのマシンで推論の計算を行うというような構造である.
このような複数の計算機を同時に走らせるようなアプリケーションをクラウド上で実現するには,どのようにすればよいのだろうか?
重要なポイントとして, figure_title や figure_title で起動している複数のマシンは,基本的に全く同一の OS・計算環境を有している点である. ここで,個人のコンピュータで行うようなインストールの操作を,各マシンで行うこともできるが,それは大変な手間であるし,メンテナンスも面倒だろう. すなわち,大規模な計算システムを構築するには,簡単に計算環境を複製できるような仕組みが必要であるということがわかる.
そのような目的を実現するために使われるのが, Docker とよばれるソフトウェアである.
Docker とは

Docker とは, コンテナ (Container) とよばれる仮想環境下で,ホスト OS とは独立した別の計算環境を走らせるためのソフトウェアである. Docker を使うことで, OS を含めたすべてのプログラムをコンパクトにパッケージングすることが可能になる (パッケージされた一つの計算環境のことを **イメージ (Image)**とよぶ). Docker を使うことで,クラウドのサーバー上に瞬時に計算環境を複製することが可能になり, figure_title で見たような複数の計算機を同時に走らせるためのシステムが実現できる.
Docker は 2013 年に Solomon Hykes らを中心に開発され,それ以降爆発的に普及し,クラウドコンピューティングだけでなく,機械学習・科学計算の文脈などでも欠かすことのできないソフトウェアとなった. Docker はエンタープライズ向けの製品を除き無料で使用することができ,コアの部分は オープンソースプロジェクト として公開されている. Docker は Linux, Windows, Mac いずれの OS でも提供されている. 概念としては, Docker は仮想マシン (Virtual machine; VM) にとても近い. ここでは, VM との対比をしながら,Docker とはなにかを簡単に説明しよう.
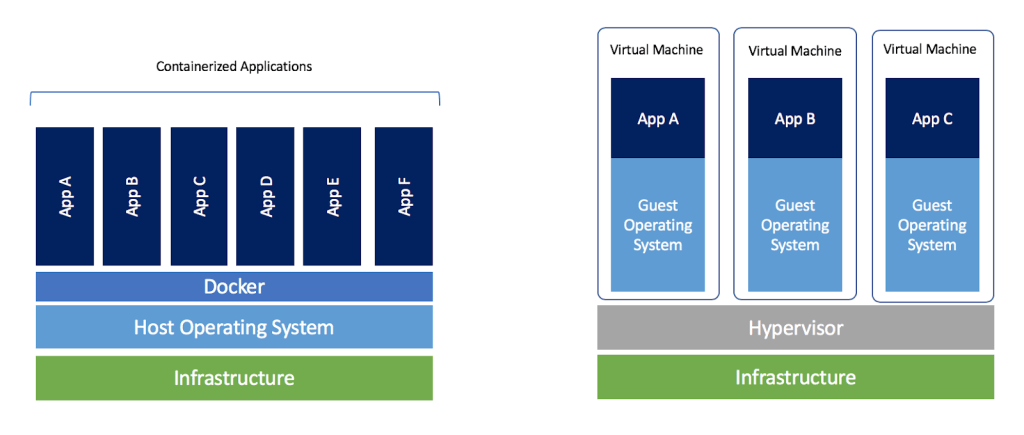
仮想マシン (VM) とは,ホストとなるマシンの上に,仮想化された OS を走らせる技術である (figure_title). VM には ハイパーバイザー (Hypervisor) とよばれるレイヤーが存在する. Hypervisor はまず,物理的な計算機リソース (CPU, RAM, network など) を分割し,仮想化する. たとえば, ホストマシンに物理的な CPU が 4 コアあるとして,ハイパーバイザーはそれを (2,2) 個の組に仮想的に分割することができる. VM 上で起動する OS には,ハイパーバイザーによって仮想化されたハードウェアが割り当てられる. VM 上で起動する OS は基本的に完全に独立であり,たとえば OS-A は OS-B に割り当てられた CPU やメモリー領域にアクセスすることはできない (これを isolation とよぶ). VM を作成するための有名なソフトウェアとしては, VMware, VirtualBox, Xen などがある. また,これまで触ってきた EC2 も,基本的に VM 技術を使うことで所望のスペックをもった仮想マシンがユーザーに提示される.
Docker も, VM と同様に,仮想化された OS をホストの OS 上に走らせるための技術である. VM に対し, Docker ではハードウェアレベルの仮想化は行われておらず,すべての仮想化はソフトウェアレベルで実現されている (figure_title). Docker で走る仮想 OS は,多くの部分をホストの OS に依存しており,結果として非常にコンパクトである. その結果, Docker で仮想 OS を起動するために要する時間は, VM に比べて圧倒的に早い. また, パッケージ化された環境 (=イメージ) のサイズも完全な OS に比べ圧倒的に小さくなるので,ネットワークを通じたやり取りが非常に高速化される点も重要である 加えて, VM のいくつかの実装では,メタル (仮想化マシンに対して,物理的なハードウェア上で直接起動する場合のこと) と比べ,ハイパーバイザーレイヤーでのオーバーヘッドなどにより性能が低下することが知られているが, Docker ではメタルとほぼ同様の性能を引き出すことができるとされている.
その他, VM との相違点などはたくさんあるのだが,ここではこれ以上詳細には立ち入らない. 大事なのは, Docker とはとてもコンパクトかつハイパフォーマンスな仮想計算環境を作るツールである,という点である. その手軽さゆえに,2013 年の登場以降,クラウドシステムでの利用が急速に増加し,現代のクラウドでは欠くことのできない中心的な技術になっている.
職業的プログラマーにとっての"三種の神器"とはなんだろうか? 多様な意見があると思うが,筆者は Git, Vim そして Docker を挙げたい.
Git は多くの読者がご存じの通り,コードの変更を追跡するためのシステムである. Linux の作成者である Linus Torvalds によって 2005 年に誕生した. チームでの開発を進める際には欠かせないツールだ.
Vim は 1991 年から 30 年以上の間プログラマーたちに愛されてきたテキストエディターである. Stackoverflow が行った 2019 年のアンケート によると,開発環境の部門で 5 位の人気を獲得している. たくさんのショートカットと様々なカスタム設定が提供されているので,初見の人にはなかなかハードルが高いが,一度マスターすれば他のモダンなエディターや統合開発環境に負けない,あるいはそれ以上の開発体験を実現することができる.
これらの十年以上の歴史あるツールに並んで,第三番目の三種の神器として挙げたいのが Docker だ. Docker はプログラマーの開発のワークフローを一変させた. たとえば,プロジェクトごとに Docker イメージを作成することで,どの OS・コンピュータ でも全く同じ計算環境で開発・テストを実行することができるようになった. また, DevOps や CI / CD (Continuous Integration / Continuous Deployment) といった最近の開発ワークフローも Docker のようなコンテナ技術の存在に立脚している. さらにはサーバーレスコンピューティング ( (#sec_serverless)) といった概念も,コンテナ技術の生んだ大きな技術革新といえる.
あなたにとっての三種の神器はなんだろうか? また,これからの未来ではどんな新しいツールが三種の神器としてプログラマーのワークフローを革新していくだろうか?
Docker チュートリアル
Docker とはなにかを理解するためには,実際に触って動かしてみるのが一番有効な手立てである. ここでは, Docker の簡単なチュートリアルを行っていく.
Docker のインストールについては, (#sec:install_docker) および 公式のドキュメンテーション を参照してもらいたい. Docker のインストールが完了している前提で,以下は話を進めるものとする.
Docker 用語集
Docker を使い始めるに当たり,最初に主要な用語を解説しよう. 次のパラグラフで太字で強調された用語を頭に入れた上で,続くチュートリアルに取り組んでいただきたい.
Docker を起動する際の大まかなステップを示したのが figure_title である. パッケージされた一つの計算環境のことを **イメージ (Image)**とよぶ. イメージは, Docker Hub などのリポジトリで配布されているものをダウンロードするか,自分でカスタムのイメージを作成することも可能である. イメージを作成するための”レシピ”を記述したファイルが Dockerfile である. Dockerfile からイメージを作成する操作を build とよぶ. イメージがホストマシンのメモリにロードされ,起動状態にある計算環境のことを コンテナ (Container) とよぶ. Container を起動するために使用されるコマンドが run である.

イメージをダウンロード
パッケージ化された Docker の仮想環境 (= イメージ (Image)) は, Docker Hub からダウンロードできる. Docker Hub には,個人や企業・団体が作成した Docker イメージが集められており, GitHub などと同じ感覚で,オープンな形で公開されている.
たとえば, Ubuntu のイメージは Ubuntu の公式リポジトリ で公開されており, pull コマンドを使うことでローカルにダウンロードすることができる.
sh
$ docker pull ubuntu:18.04$ docker pull ubuntu:18.04ここで,イメージ名の : (コロン) 以降に続く文字列を タグ (tag) と呼び,主にバージョンを指定するなどの目的で使われる.
pull コマンドはデフォルトでは Docker Hub でイメージを検索し,ダウンロードを行う. Docker イメージを公開するためのデータベース (レジストリ (registry) とよぶ) は Docker Hub だけではなく,たとえば GitLab や GitHub は独自のレジストリ機能を提供しているし,個人のサーバーでレジストリを立ち上げることも可能である. Docker Hub 以外のレジストリから pull するには, myregistry.local:5000/testing/test-image のように,イメージ名の先頭につける形でレジストリのアドレス (さらにオプションとしてポート番号) を指定する.
コンテナを起動
Pull してきたイメージを起動するには, run コマンドを使う.
sh
$ docker run -it ubuntu:18.04$ docker run -it ubuntu:18.04ここで, -it とは,インタラクティブな shell のセッションを開始するために必要なオプションである.
このコマンドを実行すると,仮想化された Ubuntu が起動され,コマンドラインからコマンドが打ち込めるようになる (figure_title). このように起動状態にある計算環境 (ランタイム) のことを Container (コンテナ) とよぶ.

ここで使用した ubuntu:18.04 のイメージは,空の Ubuntu OS だが,すでにプログラムがインストール済みのものもある. これは, (#sec_jupyter_and_deep_learning) でみた DLAMI と概念として似ている. たとえば, PyTorch がインストール済みのイメージは PyTorch 公式の Docker Hub リポジトリ で公開されている.
これを起動してみよう.
sh
$ docker run -it pytorch/pytorch$ docker run -it pytorch/pytorchdocker run を実行したとき,ローカルに該当するイメージが見つからない場合は,自動的に Docker Hub からダウンロードされる.
pytorch のコンテナが起動したら, Python のシェルを立ち上げて, pytorch をインポートしてみよう.
sh
$ python3
Python 3.7.7 (default, May 7 2020, 21:25:33)
[GCC 7.3.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> torch.cuda.is_available()
False$ python3
Python 3.7.7 (default, May 7 2020, 21:25:33)
[GCC 7.3.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> torch.cuda.is_available()
Falseこのように, Docker を使うことで簡単に特定の OS・プログラムの入った計算環境を再現することが可能になる.
自分だけのイメージを作る
自分の使うソフトウェア・ライブラリがインストールされた,自分だけのイメージを作ることも可能である.
たとえば, 本書のハンズオン実行用に提供している docker イメージ には, Python, Node.js, AWS CLI, AWS CDK などのソフトウェアがインストール済みであり,ダウンロードしてくるだけですぐにハンズオンのプログラムが実行できるようになっている.
カスタムの docker イメージを作るには, Dockerfile という名前のついたファイルを用意し,その中にどんなプログラムをインストールするかなどを記述していく.
具体例として,本書で提供している Docker イメージのレシピを見てみよう (docker/Dockerfile).
dockerfile
FROM node:12
LABEL maintainer="Tomoyuki Mano"
RUN apt-get update \
&& apt-get install nano
#
RUN cd /opt \
&& curl -q "https://www.python.org/ftp/python/3.7.6/Python-3.7.6.tgz" -o Python-3.7.6.tgz \
&& tar -xzf Python-3.7.6.tgz \
&& cd Python-3.7.6 \
&& ./configure --enable-optimizations \
&& make install
RUN cd /opt \
&& curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" \
&& unzip awscliv2.zip \
&& ./aws/install
#
RUN npm install -g aws-cdk@1.100
# clean up unnecessary files
RUN rm -rf /opt/*
# copy hands-on source code in /root/
COPY handson/ /root/handsonFROM node:12
LABEL maintainer="Tomoyuki Mano"
RUN apt-get update \
&& apt-get install nano
#
RUN cd /opt \
&& curl -q "https://www.python.org/ftp/python/3.7.6/Python-3.7.6.tgz" -o Python-3.7.6.tgz \
&& tar -xzf Python-3.7.6.tgz \
&& cd Python-3.7.6 \
&& ./configure --enable-optimizations \
&& make install
RUN cd /opt \
&& curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" \
&& unzip awscliv2.zip \
&& ./aws/install
#
RUN npm install -g aws-cdk@1.100
# clean up unnecessary files
RUN rm -rf /opt/*
# copy hands-on source code in /root/
COPY handson/ /root/handsonDockerfile の中身の説明は詳しくは行わないが,たとえば上のコードで <1> で示したところは, Python 3.7 のインストールを実行している. また, <2> で示したところは, AWS CDK のインストールを行っていることがわかるだろう. このように,リアルな OS で行うのと同じ流れでインストールのコマンドを逐一記述していくことで,自分だけの Docker イメージを作成することができる. 一度イメージを作成すれば,それを配布することで,他者も同一の計算環境を簡単に再構成することができる.
"ぼくの環境ではそのプログラム走ったのにな…" というのは,プログラミング初心者ではよく耳にする会話だが, Docker を使いこなせばそのような心配とは無縁である. そのような意味で,クラウド以外の場面でも, Docker の有用性・汎用性は極めて高い.
コンテナを用いた仮想計算環境ツールとして Docker を紹介したが, ほかに選択肢はないのか? よくぞ聞いてくれた! Docker の登場以降,複数のコンテナベースの仮想環境ツールが開発されてきた. いずれのツールも,概念や API については Docker と共通するものが多いが,Docker にはない独自の特徴を提供している. ここではその中でも有名ないくつかを紹介しよう.
Singularity は科学計算や HPC (High Performance Computing) の分野で人気の高いコンテナプラットフォームである. Singularity では大学・研究機関の HPC クラスターでの運用に適したような設計が施されている. たとえば, Docker は基本的には root 権限で実行されるのに対し, Singularity はユーザー権限 (コマンドを実行したユーザー自身) でプログラムが実行される. root 権限での実行は Web サーバーのように個人・企業がある特定のサービスのために運用するサーバーでは問題ないが,多数のユーザーが多様な目的で計算を実行する HPC クラスターでは問題となる. また,Singularity は独自のイメージの作成方法・エコシステムをもっているが, Docker イメージを Singularity のイメージに変換し実行する機能も有している.
podman は Red Hat 社によって開発されたもう一つのコンテナプラットフォームである. podman は基本的に Docker と同一のコマンドを採用しているが,実装は Red Hat によってスクラッチから行われた. podman では, Singularity と同様にユーザー権限でのプログラムの実行を可能であり,クラウドおよび HPC の両方の環境に対応するコンテナプラットフォームを目指して作られた. また,その名前にあるとおり pod とよばれる独自の概念が導入されている.
著者の個人的な意見としては,現時点では Docker をマスターしておけば当面は困ることはないと考えるが,興味のある読者はぜひこれらのツールも試してみてはいかがだろうか?
Elastic Container Service (ECS)

ここまでに説明してきたように, Docker を使うことで仮想計算環境を簡単に複製・起動することが可能になる. 本章の最後の話題として, AWS 上で Docker を使った計算システムを構築する方法を解説しよう.
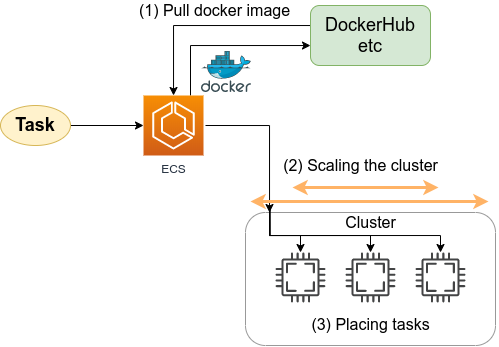
Elastic Container Service (ECS) とは, Docker を使った計算機クラスターを AWS 上に作成するためのツールである (figure_title). ECS を使用することで, Docker にパッケージされたアプリケーションを計算機クラスターに投入したり,計算機クラスターのインスタンスを追加・削除する操作 (=スケーリング) を行うことができる.
ECS の概要を示したのが figure_title である. ECS は,タスク (Task) と呼ばれる単位で管理された計算ジョブを受け付ける. システムにタスクが投入されると,ECS は最初にタスクで指定された Docker イメージを外部レジストリからダウンロードしてくる. 外部レジストリとしては, Docker Hub や AWS 独自の Docker レジストリである ECR (Elastic Container Registry) を指定することができる.
ECS の次の重要な役割はタスクの配置である. あらかじめ定義されたクラスター内で,計算負荷が小さい仮想インスタンスを選び出し,そこに Docker イメージを配置することで指定された計算タスクが開始される. "計算負荷が小さい仮想インスタンスを選び出す" と言ったが,具体的にどのような戦略・ポリシーでこの選択を行うかは,ユーザーの指定したパラメータに従う.
また,クラスターのスケーリングも ECS における重要な概念である. スケーリングとは,クラスター内のインスタンスの計算負荷をモニタリングし,計算負荷に応じてインスタンスの起動・停止を行う操作を指す. クラスター全体の計算負荷が指定された閾値 (たとえば 80%の稼働率) を超えていた場合,新たな仮想インスタンスをクラスター内に立ち上げる操作を scale-out (スケールアウト) とよび, 負荷が減った場合に不要なインスタンスを停止する操作を scale-in (スケールイン) とよぶ. クラスターのスケーリングは, ECS がほかの AWS のサービスと連携することで実現される. 具体的には, EC2 の Auto scaling group (ASG) や Fargate の2つの選択肢が多くの場合選択される. ASG については (#sec_aws_batch), Fargate については (#sec_fargate_qabot) でより詳細に解説する.
これら一連のタスクの管理を, ECS は自動でやってくれる. クラスターのスケーリングやタスクの配置に関してのパラメータを一度指定してしまえば,ユーザーは (ほとんどなにも考えずに) 大量のタスクを投入することができる. クラスターのスケーリングによってタスクの量にちょうど十分なだけのインスタンスが起動し,タスクが完了した後は不要なインスタンスはすべて停止される.
さて,ここまで説明的な話が続いてしまったが,次章からは早速 Docker と AWS を使って大規模な並列計算システムを構築していこう!